 Fakir
Fakir

 инфо
инфо инструменты
инструменты Naib
Naib

 Invar
Invar

 Sandro
Sandro

 Татарин
Татарин

 Верный союзник с Окинавы
Верный союзник с Окинавы
 Реклама Google — средство выживания форумов :)
Реклама Google — средство выживания форумов :)
-
![[image]](https://www.balancer.ru/cache/sites/co/ib/ibb/i/9sRPLxN/128x128-crop/Screenshot-2023-04-18-19-16-07-887-org-telegram-messenger.png)
Нейросеть GPT-4
Какой толк от этой страшилки?Теги:
Татарин> Сейчас мы сделали машину, которая самостоятельно приобретает опыт, который будет использован в её дальнейшем функционировании.
"Прирабатывающиеся" машины по сути "поступали" так уже много-много лет. Там приработается, там "затечёт".
Я утрирую, но ради наглядности. Не то чтоб очень уж. То есть в принципе "приобретение опыта, который будет использован в её дальнейшем функционировании" - не то чтобы качественно ново.
Татарин> Скайнет не обязательно должен "осознавать себя", уметь тонко чувствовать и писать стихи, ему вполне достаточно выцепить абстракции более глубокие, чем доступны человеку, и действовать по ним.
Пока нет какого-то потенциально опасного и вредоносного непредсказуемого внутреннего мотива или внешне поставленного задания - ну и что? Чем оно опаснее просто МБР с мегатонной головой в шахте, или ядерного реактора, или химзавода, или плотины?
Ну выцепил, ну действует.
Брошенный камень сотни тысяч лет успешно выцеплял и использовал абстракцию параболы, более глубокую, чем была доступна бросавшему человеку и прачеловеку.
Татарин> Это же реально глупо, тыкать пальцем - о! я вижу матрицу корреляции, вот эта цифирь, которая связывает "человека" и "пулемёт", это простое численное значение, оно насквозь понятно! Цифиря - конечно, понятна. Что в ней может быть непонятного?
В этой комбинации - "человек и пароход", простите, "человек и пулемёт" - с каждой из частей понятна потенциальная опасность. Пулемёт есть орудие, достаточное мощное средство, потенциально способное нанести повреждение и убить. Человек - субъект, обладающий волей (своей, навязанной - не суть) - и потенциально способный эту волю приложить к объекту-пулемёту.
Тут примерно понятно, чего бояться, кого бояться, и чего от кого ждать. И кто на самом деле представляет опасность.
ИИ. Где он в этой цепочке? На месте человека, или на месте пулемёта, или он третий лишний? Ну или не лишний, но нифига не определяющий - типа каких-нибудь защитных очков на пулемётчике, или усовершенствованного станка пулемёта.
Татарин> Конечный результат применения подобных систем может на выходе дать нечто абсолютно неуправляемое, для чего ты сам будет эффективным объектом управления.
В принципе такое представимо. Но должны быть выполнены некоторые условия. Как минимум - постановка задачи об управлении мною/тобою/им (внешняя постановка или самовозникновение такой задачи внутрии ИИ - и тут уже не получится отмахиваться от вопроса, "как там он мыслит", потому что следует понять, насколько такое самозарождение вообще возможно или невозможно), а к задаче - средства воздействия. Ну, как бы по-змеиному мудр и злонамерен он не был, но если у него нет эффекторов для воздействия на меня - пулемётов, кнутов, принтеров в Парламенте, телефонов к генералам и прокурорам, ну хотя бы типографий ежедневных газет и собственно канала на Ютубе и т.п. - если он просто чёрный ящик без серьёзных выводных устройств, то никак об эффективном управлении мною/тобою/им говорить не приходится. Ну если только ты не веришь, что при какой-то степени развития он станет еще и телепатом. Помыслить можно и такое, но верить в подобное я уже категорически отказываюсь, и рассматривать такой вариант - тоже.
Следовательно, весь вопрос в том, какие эффекторы подключены к ИИ. Какие, кем, зачем, как.
И это оставляяя пока за скобками вопрос - когда это может стать технически реализуемым.
Татарин> Есть вопросы, которые, в силу из сложности и глубины, людям не под силу, потому что время на решение растёт экспотенциально от сложности. Если машина может преодолеть барьер сложности - не так и важно, что она работает вдвое дольше, чем человек.
Да, да. Всё так. Но я никак не могу врубиться - что ты в этом видишь такого экстремально ужасного для человечества в целом?
Ну удастся решить за десятилетие работы машины какие-нибудь иначе вообще нерешаемые вопросы. Что-то открыть или доказать. Где, в котором месте начинать рвать волосы?
Чем оно принципиально хуже прозрения какого-нибудь единичного человеческого гения?
Нечто подобное было всегда.
Для каких-то государств, не обладающих подобное техникой, это безусловно может быть смертельно опасно. Ну так отставать в научно-технически-экономическом плане всегда опасно.
Но где опасность для обладателя? Она неочевидна. Ну, не более очевидна, чем опасность обладания ядерными мощностями или химзаводами.
"Прирабатывающиеся" машины по сути "поступали" так уже много-много лет. Там приработается, там "затечёт".
Я утрирую, но ради наглядности. Не то чтоб очень уж. То есть в принципе "приобретение опыта, который будет использован в её дальнейшем функционировании" - не то чтобы качественно ново.
Татарин> Скайнет не обязательно должен "осознавать себя", уметь тонко чувствовать и писать стихи, ему вполне достаточно выцепить абстракции более глубокие, чем доступны человеку, и действовать по ним.
Пока нет какого-то потенциально опасного и вредоносного непредсказуемого внутреннего мотива или внешне поставленного задания - ну и что? Чем оно опаснее просто МБР с мегатонной головой в шахте, или ядерного реактора, или химзавода, или плотины?
Ну выцепил, ну действует.
Брошенный камень сотни тысяч лет успешно выцеплял и использовал абстракцию параболы, более глубокую, чем была доступна бросавшему человеку и прачеловеку.
Татарин> Это же реально глупо, тыкать пальцем - о! я вижу матрицу корреляции, вот эта цифирь, которая связывает "человека" и "пулемёт", это простое численное значение, оно насквозь понятно! Цифиря - конечно, понятна. Что в ней может быть непонятного?
В этой комбинации - "человек и пароход", простите, "человек и пулемёт" - с каждой из частей понятна потенциальная опасность. Пулемёт есть орудие, достаточное мощное средство, потенциально способное нанести повреждение и убить. Человек - субъект, обладающий волей (своей, навязанной - не суть) - и потенциально способный эту волю приложить к объекту-пулемёту.
Тут примерно понятно, чего бояться, кого бояться, и чего от кого ждать. И кто на самом деле представляет опасность.
ИИ. Где он в этой цепочке? На месте человека, или на месте пулемёта, или он третий лишний? Ну или не лишний, но нифига не определяющий - типа каких-нибудь защитных очков на пулемётчике, или усовершенствованного станка пулемёта.
Татарин> Конечный результат применения подобных систем может на выходе дать нечто абсолютно неуправляемое, для чего ты сам будет эффективным объектом управления.
В принципе такое представимо. Но должны быть выполнены некоторые условия. Как минимум - постановка задачи об управлении мною/тобою/им (внешняя постановка или самовозникновение такой задачи внутрии ИИ - и тут уже не получится отмахиваться от вопроса, "как там он мыслит", потому что следует понять, насколько такое самозарождение вообще возможно или невозможно), а к задаче - средства воздействия. Ну, как бы по-змеиному мудр и злонамерен он не был, но если у него нет эффекторов для воздействия на меня - пулемётов, кнутов, принтеров в Парламенте, телефонов к генералам и прокурорам, ну хотя бы типографий ежедневных газет и собственно канала на Ютубе и т.п. - если он просто чёрный ящик без серьёзных выводных устройств, то никак об эффективном управлении мною/тобою/им говорить не приходится. Ну если только ты не веришь, что при какой-то степени развития он станет еще и телепатом. Помыслить можно и такое, но верить в подобное я уже категорически отказываюсь, и рассматривать такой вариант - тоже.
Следовательно, весь вопрос в том, какие эффекторы подключены к ИИ. Какие, кем, зачем, как.
И это оставляяя пока за скобками вопрос - когда это может стать технически реализуемым.
Татарин> Есть вопросы, которые, в силу из сложности и глубины, людям не под силу, потому что время на решение растёт экспотенциально от сложности. Если машина может преодолеть барьер сложности - не так и важно, что она работает вдвое дольше, чем человек.
Да, да. Всё так. Но я никак не могу врубиться - что ты в этом видишь такого экстремально ужасного для человечества в целом?
Ну удастся решить за десятилетие работы машины какие-нибудь иначе вообще нерешаемые вопросы. Что-то открыть или доказать. Где, в котором месте начинать рвать волосы?
Чем оно принципиально хуже прозрения какого-нибудь единичного человеческого гения?
Нечто подобное было всегда.
Для каких-то государств, не обладающих подобное техникой, это безусловно может быть смертельно опасно. Ну так отставать в научно-технически-экономическом плане всегда опасно.
Но где опасность для обладателя? Она неочевидна. Ну, не более очевидна, чем опасность обладания ядерными мощностями или химзаводами.


Татарин> Мы же говорим не о конкретной системе, которая сидит в конкретной коробке, а о том, что весёлая, неугомонная и никем не контролируемая толпа человеков добралась до штуковин, работы которых не понимает и по принципу построения штуковин вообще не может предсказать и контролировать.
В принципе это относится не менее чем к 50% всех используемых за всю историю человечества технологий, а то и к 90%, если в детали вглядываться. Но мир еще держится.
Татарин> То есть, главная проблема в том, что сейчас бородатый математик что-то такое придумает, потом сопливый энтузиаст чем-то таким простым дополнит, а потом в какой-то оборонной конторе дополнят. Или наоборот.
...и где, в каком месте, тут особая роль ИИ (и тем более доступного сейчас или завтра ИИ), ведущая к качественным переменам?
"Джентльмены в форме теоремы воплотят... Гарри торжествует, все о Гарри говорят, а его изделия летают" © фольклор 60-х
Татарин> И этих червей обратно в банку не утолкать.
Так было, так будет.
Но черви от этого не становятся автоматически шай-хулудами.
Татарин> Куда и как всё это будет присобачиваться - вот фиг знает, но насчёт тех же военных применений - будь уверен на 100%.
Так было, так будет.
Татарин> В какой-то момент мы можем перейти черту, из-за которой нет возврата, и которая поделит всё на "до" и "после". Но уже не для людей.")
Наверное, это мыслимо. Но для этого нужно очень-очень многое. Мало построить Массачусетскую машину, мало её отладить и обеспечить подачу электроэнергии - надо еще очень много чего наподключать. До того это в самом кризисном случае - бодливая корова без рогов, без копыт, и даже мычать не может.
В принципе это относится не менее чем к 50% всех используемых за всю историю человечества технологий, а то и к 90%, если в детали вглядываться. Но мир еще держится.
Татарин> То есть, главная проблема в том, что сейчас бородатый математик что-то такое придумает, потом сопливый энтузиаст чем-то таким простым дополнит, а потом в какой-то оборонной конторе дополнят. Или наоборот.
...и где, в каком месте, тут особая роль ИИ (и тем более доступного сейчас или завтра ИИ), ведущая к качественным переменам?
"Джентльмены в форме теоремы воплотят... Гарри торжествует, все о Гарри говорят, а его изделия летают" © фольклор 60-х
Татарин> И этих червей обратно в банку не утолкать.
Так было, так будет.
Но черви от этого не становятся автоматически шай-хулудами.
Татарин> Куда и как всё это будет присобачиваться - вот фиг знает, но насчёт тех же военных применений - будь уверен на 100%.
Так было, так будет.
Татарин> В какой-то момент мы можем перейти черту, из-за которой нет возврата, и которая поделит всё на "до" и "после". Но уже не для людей.
")
Наверное, это мыслимо. Но для этого нужно очень-очень многое. Мало построить Массачусетскую машину, мало её отладить и обеспечить подачу электроэнергии - надо еще очень много чего наподключать. До того это в самом кризисном случае - бодливая корова без рогов, без копыт, и даже мычать не может.
Татарин> Просто эта штука на обучении верит всему абсолютно, как 3-летний ребёнок (а скорее - как младенец). Она не "умеет" иначе, её напрямую заливают данными.
На данном этапе хорошо бы просто обучить её на 100% доверенных данных, кое-как вышло, и уже практически значимые результаты есть.
А где ж их взять? Процесс уже запущен и упущен. И уже давно - первый раз проблему инфомусора в научных публикациях и патентах я поднимал лет 20 назад (а она началась где-то в 90-е ещё). С предложением создания верифицированных баз знаний. И даже соцсеточку типа линкедина предлагал запилить. Не срослось
Татарин> Собссно, "критическое мышление" и дообучение в процессе работы - следующий этап. Он будет, ессно. Просто тут требуется другой, более сложный код и, боюсь, куда бОльший размер моделей. Потому что глубина паттернов с включением концепции лжи растёт очень быстро.
И в итоге всё одно упрёшься в личный опыт. Практика - критерий истины. Придёшь к вопросам, которые невозможно разрешить теоретически, а нужно проверять экспериментом. И хорошо ещё если там всё пойдёт по прогнозируемому пути, а не сикось-накось как обычно...
На данном этапе хорошо бы просто обучить её на 100% доверенных данных, кое-как вышло, и уже практически значимые результаты есть.
А где ж их взять? Процесс уже запущен и упущен. И уже давно - первый раз проблему инфомусора в научных публикациях и патентах я поднимал лет 20 назад (а она началась где-то в 90-е ещё). С предложением создания верифицированных баз знаний. И даже соцсеточку типа линкедина предлагал запилить. Не срослось
Татарин> Собссно, "критическое мышление" и дообучение в процессе работы - следующий этап. Он будет, ессно. Просто тут требуется другой, более сложный код и, боюсь, куда бОльший размер моделей. Потому что глубина паттернов с включением концепции лжи растёт очень быстро.
И в итоге всё одно упрёшься в личный опыт. Практика - критерий истины. Придёшь к вопросам, которые невозможно разрешить теоретически, а нужно проверять экспериментом. И хорошо ещё если там всё пойдёт по прогнозируемому пути, а не сикось-накось как обычно...


Татарин> Тут то же самое, но применительно к семантическим сетям и любым токенизируемым данным (код, формальное описание цепочек действий, логических электронных схем, перевод, диалог, составление рефератов и выжимка из текстов на естественных языках и т.п.). При этом машина научилась составлять семантические сети из текстов на естественном языке, научилась "понимать" (или даже понимать) естественный текст
Вот кстати!
Когда - и если - сетка сумеет сделать действительно качественную выжимку из сложного осмысленного текста, осмысленную выжимку а не тупой студенческий реферат, где не пропущено действительно важное, и опущена вся вода - это будет действительно поводом напрячься. Даже не знаю, почему именно, но напрячься и присмотреться будет надо. В сущности это уже тест на мышление или что-то к нему близкое, а не имитацию.
Вот кстати!
Когда - и если - сетка сумеет сделать действительно качественную выжимку из сложного осмысленного текста, осмысленную выжимку а не тупой студенческий реферат, где не пропущено действительно важное, и опущена вся вода - это будет действительно поводом напрячься. Даже не знаю, почему именно, но напрячься и присмотреться будет надо. В сущности это уже тест на мышление или что-то к нему близкое, а не имитацию.
Татарин> У меня не хватает воображения придумать конкретную причину, по которой машина может научиться играть в го или писать детские рассказы, но не может написать теорию электрослабого взаимодействия. Я вижу тут количественную, а не качественную разницу.
Татарин> Я не понимаю, как и почему вы проводите между этими вещами черту.
Ну тут-то по-моему как раз всё просто.
Наверное, нет препятствий для того, чтобы в рамках любой заданной формализованной системы машина смогла бы вывести или доказать любой результат, если он в рамках этой системы вообще выводим и доказуем.
Но для создания новой теории, как правило, нужно введение новых аксиом.
И как вот это будет делать машина - я пока не очень понимаю. То есть, честно говоря, совсем не понимаю.
Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...
Татарин> Я не понимаю, как и почему вы проводите между этими вещами черту.
Ну тут-то по-моему как раз всё просто.
Наверное, нет препятствий для того, чтобы в рамках любой заданной формализованной системы машина смогла бы вывести или доказать любой результат, если он в рамках этой системы вообще выводим и доказуем.
Но для создания новой теории, как правило, нужно введение новых аксиом.
И как вот это будет делать машина - я пока не очень понимаю. То есть, честно говоря, совсем не понимаю.
Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...

Invar>> И это самая страшная тайна ИИ. Авторитетно  выглядящая чушь
выглядящая чушь
Invar>> На текущий момент ни напалма, ни ракеты по его советам
по его советам
Naib> Ну, напалм и ракету к нему я тебе и так насоветовать могу.") Но может не нать?
Но может не нать? 
Немного запоздал с советами.
Грят, в начале 19 века уже Копенгаген сожгли,ещё с машиной Бэббиджа
Но шо интересно, скоро, а может и уже имеем войну машин:
Одни генерят и тиражируют подобный правдоподобный бред, вторые комнадзоровско-прокурорские его запрещают по ключевым словам "пошлите ключницу в погреб за 10 фунтами оружейного калифорния"
Кипит бурная имитация, приближая тепловую смерть Вселенной!
А если и приговоры машина выносить бут...
Или с участием "оператора" с IQ60 - аля Идиократия
 выглядящая чушь
выглядящая чушьInvar>> На текущий момент ни напалма, ни ракеты
 по его советам
по его советамNaib> Ну, напалм и ракету к нему я тебе и так насоветовать могу.
") Но может не нать?
Но может не нать? 
Немного запоздал с советами.
Грят, в начале 19 века уже Копенгаген сожгли,
Но шо интересно, скоро, а может и уже имеем войну машин:
Одни генерят и тиражируют подобный правдоподобный бред, вторые комнадзоровско-прокурорские его запрещают по ключевым словам "пошлите ключницу в погреб за 10 фунтами оружейного калифорния"
Кипит бурная имитация, приближая тепловую смерть Вселенной!
А если и приговоры машина выносить бут...
Или с участием "оператора" с IQ60 - аля Идиократия
...
Invar> Или с участием "оператора" с IQ60 - аля Идиократия
Тем временем проблема нехватки врачей почти решена:

Invar> Или с участием "оператора" с IQ60 - аля Идиократия
Тем временем проблема нехватки врачей почти решена:
Чат-бот Google уже работает в больнице. Компания с апреля тестирует чат-бота на основе языковой модели Med-PaLM 2
Компания Google уже начала испытания своего искусственного интеллекта в одной из больниц США. Чат-бот на основе языковой модели Med-PaLM 2 с апреля проходит тестирование в больнице Mayo Clinic. сгенерировано нейросетью Midjourney Напомним, языковая модель PaLM 2 лежит в основе чат-бота Google Bard. // www.ixbt.comСогласно мнению самой Google, такой ИИ может быть особенно полезной в странах с «более ограниченным доступом к врачам». При этом, как и другие подобные языковые модели, она всё-таки далеко не идеальна и страдает от ряда типичных для подобных разработок проблем.
В ходе исследования врачи обнаружили больше неточностей и неактуальной информации в ответах, предоставленных Google Med-PalM 2, чем в ответах других врачей. При этом почти по всем другим показателям, таким как демонстрация доказательств рассуждений, подтвержденные консенсусом ответы или отсутствие признаков неправильного понимания, Med-PaLM 2 работал примерно на уровне врачей.
Fakir> Но для создания новой теории, как правило, нужно введение новых аксиом.
Fakir> Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...
А мы как мыслим? Из всего мыслительного мусора отбрасываем заведомый бред, остальное проверяем.
А вообще брутфорс с хорошей ранней фильтрацией даёт удивительные результаты.
Da Vinci code - Mona Lisa in 256 bytes
256-byte intro for БК 0010 - DEC PDP-11 compatible Soviet home computer. Based on Ilmenit's work released in 2014 for Atari XL. Coded by Manwe from the SandS & StroginoPC demogroups. Download executable file and source code: https://www.pouet.net/prod.php?which=86820 P.S. About file size: 376 octal means 254 decimal.
254 (376 восьмеричное) байта. Программа, рисующая портрет, найдена брутфорсом. 22032 = это немыслимо большое число, я даже приводить его тут не буду.
Однако, в море информационного шума технически реально найти даже такое.
Fakir> Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...
А мы как мыслим? Из всего мыслительного мусора отбрасываем заведомый бред, остальное проверяем.
А вообще брутфорс с хорошей ранней фильтрацией даёт удивительные результаты.
Da Vinci code - Mona Lisa in 256 bytes
256-byte intro for БК 0010 - DEC PDP-11 compatible Soviet home computer. Based on Ilmenit's work released in 2014 for Atari XL. Coded by Manwe from the SandS & StroginoPC demogroups. Download executable file and source code: https://www.pouet.net/prod.php?which=86820 P.S. About file size: 376 octal means 254 decimal.
254 (376 восьмеричное) байта. Программа, рисующая портрет, найдена брутфорсом. 22032 = это немыслимо большое число, я даже приводить его тут не буду.
Однако, в море информационного шума технически реально найти даже такое.
Sandro> Критическое осмысление как минимум поразумевает рекурсивность. То есть повторное введение в логическую систему всех же своих собстыенных предыдущих заявлений. Ну и как нормально её реализовать в сетке? А никак, поэтому вводят не совсем явное состояние, реализующееся через внешние механизмы, хоть очередь токенов. У самой-то сетки состояния нет, это же просто математическая функция по сути. D => E.
Что-то ты настолько дико гонишь, что тут уже нужно посылать к учебникам. Память в рекуррентных сетках - это же азы, да ещё и полувековой давности. Это примерно как тебе кто-то начнёт втирать, что в процессорах операции умножения нет, и она невозможна.
Собссно, без рекуррентных цепочек невозможна бОльшая часть всего того функционала, что ты знаешь - распознавание голоса, автопилоты, АСУ, обсуждаемые тут БЯМ, остаются только разросшиеся персептроны.
Не.
Есть и память, давно есть (и массово применяются! это реально азы) механизмы кратковременной памяти, долговременной, одних только механизмов забывания придумано за десяток штук. Ну сам подумай - ну как бы та же БЯМ анализировала текст и предсказывала следующие токены, если не помнит предыдущих?
В обсуждаемых БЯМ "внешняя память" для сессии нужна по другой причине, чисто практической и чисто для конкретного применения - минимизировать вычислительную работу при прямом прогоне, разделить дорогое в вычислительном плане и редко полезное (а часто даже прямо вредное!) "обучение" и "работу".
Построить БЯМ, которая "помнит" сессию "внутри" несложно, и качество работы только вырастет, скорее всего. Просто вместе с некоторым ростом качества стоимость прямого прогона РЕЗКО возрастёт, а в большинстве применений этого не нужно.
Sandro> Паттернов похожих нет — всё, труба, сетка ничего не может. Мышления же нет. Это уровень лягушки, грубо говоря. Очень хорошо эрудированной лягушки.
Ты очень узко понимаешь слово "паттерн", как некую математическую форму Ф(A)->B. Паттерн может быть (и бывает, и даже как правило бывает) таким, что включает в себя рекуррентные заходы. Он может быть очень сложным.
То, что ты, видимо, называешь "мышлением", сам процесс моего объяснения, твой процесс чтения и возмущения прочитанным с одновременным формированием возражений - и есть рекуррентный паттерн (причём, не из самых сложных, доступных тебе).
(И ты очень зря так свысока смотришь на лягушек. У них офигенный функционал. Просто ты слишком выделяешь и очень переоцениваешь наши внутренние вербализованные (токенизированные) рассуждения, забывая о том, что у тебя самого из 100 миллиарда нейронов над тем, что как-то можно отнести к "мышлению" работает менее 10. Это не значит, что остальное тебе не нужно или что оно "очень простое")
Что-то ты настолько дико гонишь, что тут уже нужно посылать к учебникам. Память в рекуррентных сетках - это же азы, да ещё и полувековой давности.
Это примерно как тебе кто-то начнёт втирать, что в процессорах операции умножения нет, и она невозможна. Собссно, без рекуррентных цепочек невозможна бОльшая часть всего того функционала, что ты знаешь - распознавание голоса, автопилоты, АСУ, обсуждаемые тут БЯМ, остаются только разросшиеся персептроны.
Не.
Есть и память, давно есть (и массово применяются! это реально азы) механизмы кратковременной памяти, долговременной, одних только механизмов забывания придумано за десяток штук. Ну сам подумай - ну как бы та же БЯМ анализировала текст и предсказывала следующие токены, если не помнит предыдущих?
В обсуждаемых БЯМ "внешняя память" для сессии нужна по другой причине, чисто практической и чисто для конкретного применения - минимизировать вычислительную работу при прямом прогоне, разделить дорогое в вычислительном плане и редко полезное (а часто даже прямо вредное!) "обучение" и "работу".
Построить БЯМ, которая "помнит" сессию "внутри" несложно, и качество работы только вырастет, скорее всего. Просто вместе с некоторым ростом качества стоимость прямого прогона РЕЗКО возрастёт, а в большинстве применений этого не нужно.
Sandro> Паттернов похожих нет — всё, труба, сетка ничего не может. Мышления же нет. Это уровень лягушки, грубо говоря. Очень хорошо эрудированной лягушки.
Ты очень узко понимаешь слово "паттерн", как некую математическую форму Ф(A)->B. Паттерн может быть (и бывает, и даже как правило бывает) таким, что включает в себя рекуррентные заходы. Он может быть очень сложным.
То, что ты, видимо, называешь "мышлением", сам процесс моего объяснения, твой процесс чтения и возмущения прочитанным с одновременным формированием возражений - и есть рекуррентный паттерн (причём, не из самых сложных, доступных тебе).
(И ты очень зря так свысока смотришь на лягушек. У них офигенный функционал. Просто ты слишком выделяешь и очень переоцениваешь наши внутренние вербализованные (токенизированные
) рассуждения, забывая о том, что у тебя самого из 100 миллиарда нейронов над тем, что как-то можно отнести к "мышлению" работает менее 10. Это не значит, что остальное тебе не нужно или что оно "очень простое")
Fakir> "Прирабатывающиеся" машины по сути "поступали" так уже много-много лет. Там приработается, там "затечёт".
Тут качественный переход.
Fakir> Пока нет какого-то потенциально опасного и вредоносного непредсказуемого внутреннего мотива или внешне поставленного задания - ну и что? Чем оно опаснее просто МБР с мегатонной головой в шахте, или ядерного реактора, или химзавода, или плотины?
Тем, что машина может сформировать себе этот опасный и вредоносный непредсказуемый внутренний мотив или поставить себе задание непредсказуемым образом.
Fakir> Следовательно, весь вопрос в том, какие эффекторы подключены к ИИ.
Нет. При достаточном уровне сложности, это уже неважно: человек, взаимодействующий с ИИ является эффектором и инструментом с относительно несложным управлением.
Нейросеть, которая управляет машиной и решает врезаться в толпу, не столь уж опасна, она может убить единицы и по сути ничем не отличается от просто заклинившей педали тормоза. Тут реально никакой принципиально новой опасности нет.
Принципиально новая опасность появляется в тот момент, когда некая нейросеть получает качественное превосходство в глубине вычисляемых паттернов над человеком.
...и если писать страшную фантастику ближнего прицела, то я бы описывал не вышедший из недр Пентагона Skynet с подключенными к нему ядерными ракетами, внезапно начавшего ядерную войну, а UndersiderNet, тихо работающего в недрах какой-нить Cambridge Analytics, который точными советами контролируемо и эффективно разжигает войны и эпидемии.
Тут качественный переход.
Fakir> Пока нет какого-то потенциально опасного и вредоносного непредсказуемого внутреннего мотива или внешне поставленного задания - ну и что? Чем оно опаснее просто МБР с мегатонной головой в шахте, или ядерного реактора, или химзавода, или плотины?
Тем, что машина может сформировать себе этот опасный и вредоносный непредсказуемый внутренний мотив или поставить себе задание непредсказуемым образом.
Fakir> Следовательно, весь вопрос в том, какие эффекторы подключены к ИИ.
Нет. При достаточном уровне сложности, это уже неважно: человек, взаимодействующий с ИИ является эффектором и инструментом с относительно несложным управлением.
Нейросеть, которая управляет машиной и решает врезаться в толпу, не столь уж опасна, она может убить единицы и по сути ничем не отличается от просто заклинившей педали тормоза. Тут реально никакой принципиально новой опасности нет.
Принципиально новая опасность появляется в тот момент, когда некая нейросеть получает качественное превосходство в глубине вычисляемых паттернов над человеком.
...и если писать страшную фантастику ближнего прицела, то я бы описывал не вышедший из недр Пентагона Skynet с подключенными к нему ядерными ракетами, внезапно начавшего ядерную войну, а UndersiderNet, тихо работающего в недрах какой-нить Cambridge Analytics, который точными советами контролируемо и эффективно разжигает войны и эпидемии.
Fakir> Но для создания новой теории, как правило, нужно введение новых аксиом.
Эээ... М? А чем "введение новых аксиом" отличается от любого другого действия?
Собссно, машина может работать в любую сторону, восстанавливая любой фрагмент паттерна, необязательно именно начиная с того, что человек условно называет "начальной точкой" или "аксиомами".
Если иметь общий рисунок, аксиомы точно так же выводятся из результатов, как и результаты из аксиом. Эти названия - чисто человеческая условность для удобства передачи информации от человека к человеку. Собссно, и люди-то работают именно таким способом, придумывая аксиомы, как часть какого-то понятого глубокого паттерна.
"Скорость света постоянна" или "магнетизм можно рассматривать как релятивисткий феномен" - не тождественны, но одно плотно связано с другим и увязано в более общий рисунок СТО. Я понимаю, что человек назовёт первое - "аксиома", а второе - "частным следствием", но по сути это срезы одного многомерного клубка сложно связанных понятий.
Если ты "взял" обзий рисунок, то все его части и частные виды под конкретными углами чисто технически выводимы (по определению; или же ты общей и полной картины не имеешь).
Fakir> И как вот это будет делать машина - я пока не очень понимаю. То есть, честно говоря, совсем не понимаю.
Я понимаю, что ты не понимаешь, я не понимаю, зачем. Чтобы не понять, ты вводишь совершенно искусственные условия, никак не помогающие тебе ни в чём... кроме как в непонимании.
Fakir> Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...
Ты пытаешься представить алгоритмическое мышление. Это даже для людей не работает.
Эээ... М? А чем "введение новых аксиом" отличается от любого другого действия?
Собссно, машина может работать в любую сторону, восстанавливая любой фрагмент паттерна, необязательно именно начиная с того, что человек условно называет "начальной точкой" или "аксиомами".
Если иметь общий рисунок, аксиомы точно так же выводятся из результатов, как и результаты из аксиом. Эти названия - чисто человеческая условность для удобства передачи информации от человека к человеку. Собссно, и люди-то работают именно таким способом, придумывая аксиомы, как часть какого-то понятого глубокого паттерна.
"Скорость света постоянна" или "магнетизм можно рассматривать как релятивисткий феномен" - не тождественны, но одно плотно связано с другим и увязано в более общий рисунок СТО. Я понимаю, что человек назовёт первое - "аксиома", а второе - "частным следствием", но по сути это срезы одного многомерного клубка сложно связанных понятий.
Если ты "взял" обзий рисунок, то все его части и частные виды под конкретными углами чисто технически выводимы (по определению; или же ты общей и полной картины не имеешь).
Fakir> И как вот это будет делать машина - я пока не очень понимаю. То есть, честно говоря, совсем не понимаю.
Я понимаю, что ты не понимаешь, я не понимаю, зачем.
Чтобы не понять, ты вводишь совершенно искусственные условия, никак не помогающие тебе ни в чём... кроме как в непонимании.Fakir> Т.е. можно придумать какие-то способы, но чтобы это вышли хорошие способы... Даже чтобы брутфорсом можно было задавить в итоге...
Ты пытаешься представить алгоритмическое мышление. Это даже для людей не работает.
Это сообщение редактировалось 13.07.2023 в 12:52
Татарин> "Скорость света постоянна" или "магнетизм можно рассматривать как релятивисткий феномен" - не тождественны, но одно плотно связано с другим и увязано в более общий рисунок ОТО. Я понимаю, что человек назовёт первое - "аксиома", а второе - "частным следствием", но по сути это срезы одного многомерного клубка сложно связанных понятий.
Так тут в теме много всего, на что надо ответить, но я сейчас чисто физически не имею времени, и так глубоко за полночь пишу. В "малые часы", как говорят англичане.
Так вот: не все аксиомы одинаково полезны. Не случайно ещё Евклид озаботился минимальной аксиоматикой. Ну, тогда тому причиной был полный бардак в аксиомах, теоремах и доказательствах, который Евклид героически разгрёб. Да так героически, что нынешние школьные учебники геометрии, а точнее планиметрии по сути являются пересказом Начал, там очень сложно что-либо добавить.
Однако, внезапно выяснилось, что, похоже, можно формулировать всё иначе, через базовые определения и теорему о синусах. Потому, что из неё можно вывести свойства треугольника, а из треугольника всю планиметрию вообще.
Т.е. это узкое место, которое находится в середине классической системы. И???
PS: А магнетизм — это и есть релятивистский феномен, связанный с тем, что ЭМ волна — поперечная. Не?
Так тут в теме много всего, на что надо ответить, но я сейчас чисто физически не имею времени, и так глубоко за полночь пишу. В "малые часы", как говорят англичане.
Так вот: не все аксиомы одинаково полезны. Не случайно ещё Евклид озаботился минимальной аксиоматикой. Ну, тогда тому причиной был полный бардак в аксиомах, теоремах и доказательствах, который Евклид героически разгрёб. Да так героически, что нынешние школьные учебники геометрии, а точнее планиметрии по сути являются пересказом Начал, там очень сложно что-либо добавить.
Однако, внезапно выяснилось, что, похоже, можно формулировать всё иначе, через базовые определения и теорему о синусах. Потому, что из неё можно вывести свойства треугольника, а из треугольника всю планиметрию вообще.
Т.е. это узкое место, которое находится в середине классической системы. И???
PS: А магнетизм — это и есть релятивистский феномен, связанный с тем, что ЭМ волна — поперечная. Не?
Sandro> Так вот: не все аксиомы одинаково полезны.
Для человека. Человеку так удобнее потому что оптимальные аксиомы создают своего рода минималистичную систему утверждений, из которой выводится остальное. Тут упор не на том, что выводится остальное (таких систем утверждений очень много), а на том, что система минималистична. В этом есть и удобство для человека, в первую очередь для обучения, для понимания принципов (которые заменяют много фактов).
Понимания принципов человеку набор аксиом всё равно не даёт, но после их изучения и работы над собой (с помощью книг, лектора, практики) он разворачивает у себя в голове полный (или неполный) паттерн, который уже и позволяет ему иметь дело со всеми (или не всеми - тут уж как понял) случаями, относящимися к теории.
Но у нас-то с Факиром ситуация не та. У нас (в ситуации вопроса Факира) есть машина, которая "поняла" теорию, из множества фактов выцепила все связи и составила паттерн.
Какая ей проблема нарисовать какую-то аксиому теории? Ровно никакой. Это просто один из выбранных фактов из этой теории. Не случайно выбранный факт, а выбранный так, чтобы составлять удобный минималистичный базис, но это уже технические детали. Только и всего.
У теории нет "начала" и нет "конца", у неё есть просто разные способы описаний.
Даже нынешние БЯМ легко приводят описание цельного явления через один набор утверждений к другому описанию другим набором утверждений.
Sandro> ...Однако, внезапно выяснилось, что, похоже, можно формулировать всё иначе, через базовые определения и теорему о синусах. Потому, что из неё можно вывести свойства треугольника, а из треугольника всю планиметрию вообще.
Sandro> Т.е. это узкое место, которое находится в середине классической системы. И???
Вот это самое "И???" - это мой вопрос Факиру.
Только я утверждаю, что тут и "узких мест" нет и не было никаких. Никаких изменений в свойствах треугольников от принятия этой аксиоматики не случилось и не случится. Формулировать можно очень по-разному, если у тебя в голове вообще есть то, что можно формулировать.
А если нет того, что можно формулировать - тогда, конечно, опаньки. Но опаньки опять же, потому, что у тебя общего понимания нет, а не потому, что ты какую-то аксиому, вишьли, придумать не можешь.
Для человека. Человеку так удобнее потому что оптимальные аксиомы создают своего рода минималистичную систему утверждений, из которой выводится остальное. Тут упор не на том, что выводится остальное (таких систем утверждений очень много), а на том, что система минималистична. В этом есть и удобство для человека, в первую очередь для обучения, для понимания принципов (которые заменяют много фактов).
Понимания принципов человеку набор аксиом всё равно не даёт, но после их изучения и работы над собой (с помощью книг, лектора, практики) он разворачивает у себя в голове полный (или неполный) паттерн, который уже и позволяет ему иметь дело со всеми (или не всеми
- тут уж как понял) случаями, относящимися к теории.Но у нас-то с Факиром ситуация не та. У нас (в ситуации вопроса Факира) есть машина, которая "поняла" теорию, из множества фактов выцепила все связи и составила паттерн.
Какая ей проблема нарисовать какую-то аксиому теории? Ровно никакой. Это просто один из выбранных фактов из этой теории. Не случайно выбранный факт, а выбранный так, чтобы составлять удобный минималистичный базис, но это уже технические детали. Только и всего.
У теории нет "начала" и нет "конца", у неё есть просто разные способы описаний.
Даже нынешние БЯМ легко приводят описание цельного явления через один набор утверждений к другому описанию другим набором утверждений.
Sandro> ...Однако, внезапно выяснилось, что, похоже, можно формулировать всё иначе, через базовые определения и теорему о синусах. Потому, что из неё можно вывести свойства треугольника, а из треугольника всю планиметрию вообще.
Sandro> Т.е. это узкое место, которое находится в середине классической системы. И???
Вот это самое "И???" - это мой вопрос Факиру.
Только я утверждаю, что тут и "узких мест" нет и не было никаких. Никаких изменений в свойствах треугольников от принятия этой аксиоматики не случилось и не случится. Формулировать можно очень по-разному, если у тебя в голове вообще есть то, что можно формулировать.
А если нет того, что можно формулировать - тогда, конечно, опаньки. Но опаньки опять же, потому, что у тебя общего понимания нет, а не потому, что ты какую-то аксиому, вишьли, придумать не можешь.
Это сообщение редактировалось 13.07.2023 в 12:53

Naib> На данном этапе хорошо бы просто обучить её на 100% доверенных данных, кое-как вышло, и уже практически значимые результаты есть.
Более того, практически подошли к лимиту кол-ва данных, которые реально хотя бы по диагонали прочитать и удостовериться в их внятности.
Naib> А где ж их взять? Процесс уже запущен и упущен. И уже давно - первый раз проблему инфомусора в научных публикациях и патентах я поднимал лет 20 назад (а она началась где-то в 90-е ещё). С предложением создания верифицированных баз знаний. И даже соцсеточку типа линкедина предлагал запилить. Не срослось.
"Проблемой создания верифицированных баз знаний" занимаются ещё с 50-х. Просто для понимания масштаба: всего на хорошую LLM уходит последовательность данных порядка нескольких ТРИЛЛИОНОВ токенов...
Более того, практически подошли к лимиту кол-ва данных, которые реально хотя бы по диагонали прочитать и удостовериться в их внятности.
Naib> А где ж их взять? Процесс уже запущен и упущен. И уже давно - первый раз проблему инфомусора в научных публикациях и патентах я поднимал лет 20 назад (а она началась где-то в 90-е ещё). С предложением создания верифицированных баз знаний. И даже соцсеточку типа линкедина предлагал запилить. Не срослось.
"Проблемой создания верифицированных баз знаний" занимаются ещё с 50-х. Просто для понимания масштаба: всего на хорошую LLM уходит последовательность данных порядка нескольких ТРИЛЛИОНОВ токенов...

Fakir> Полагаю, у фармы все соображения уже давно готовы. Машинный поиск всех видов для веществ-кандидатов давным-давно применяется, и так и эдак, и с молекулярной механикой, и с квантовохимическим моделированием, и даже про целиком тестирование до упора в электронном виде (почти без выхода в пробирку и на мышей) пишут как о перспективе более 4 лёт как.
Именно... Но в итоге попытки "создать киношную матрицу и провести всю разработку сложного продукта в киношной матрице" натыкаются на проблемы создания и поддержания (и проверки) вот такой вот матрицы...
Тут не то что химию/биохимию решить, но до сих пор нужны аэродинамические трубы и "летающие лаборатории", хотя казалось бы, газодинамика куда проще...
Именно... Но в итоге попытки "создать киношную матрицу и провести всю разработку сложного продукта в киношной матрице" натыкаются на проблемы создания и поддержания (и проверки) вот такой вот матрицы...
Тут не то что химию/биохимию решить, но до сих пор нужны аэродинамические трубы и "летающие лаборатории", хотя казалось бы, газодинамика куда проще...
Sandro> Болевые таки работают через ЦНС. Единственный прямой рефлекс — это моргательный. Там в сетчатке есть детектор пятен, резко увеличивающихся в размерах, и от него нерв прямо на мышцы. Время срабатывания порядка 40мс — в 5 раз быстрее, чем для всего прочего.
Лично мне очень нравится версия, что нервная система развилась как какая-то параллельная структура, где цепочка "сигнал сенсора - действие" очень короткая, а нервные ганглии и мозги эволюционировали позднее.
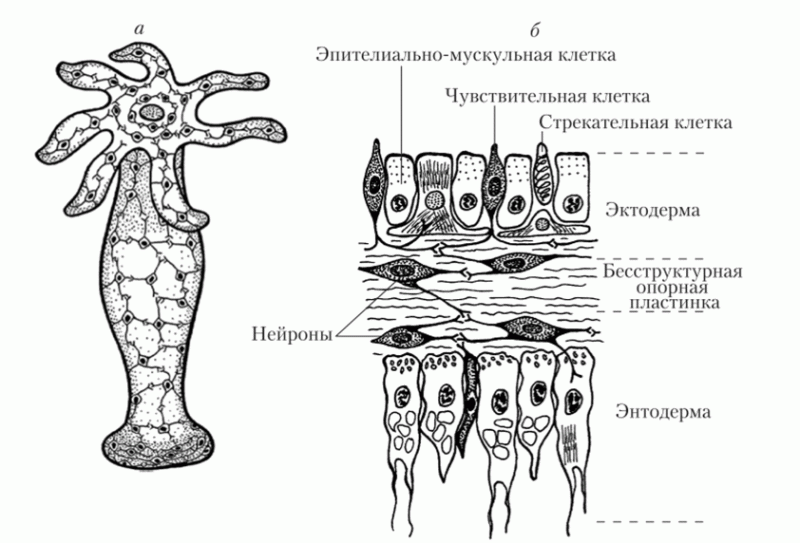
Лично мне очень нравится версия, что нервная система развилась как какая-то параллельная структура, где цепочка "сигнал сенсора - действие" очень короткая, а нервные ганглии и мозги эволюционировали позднее.
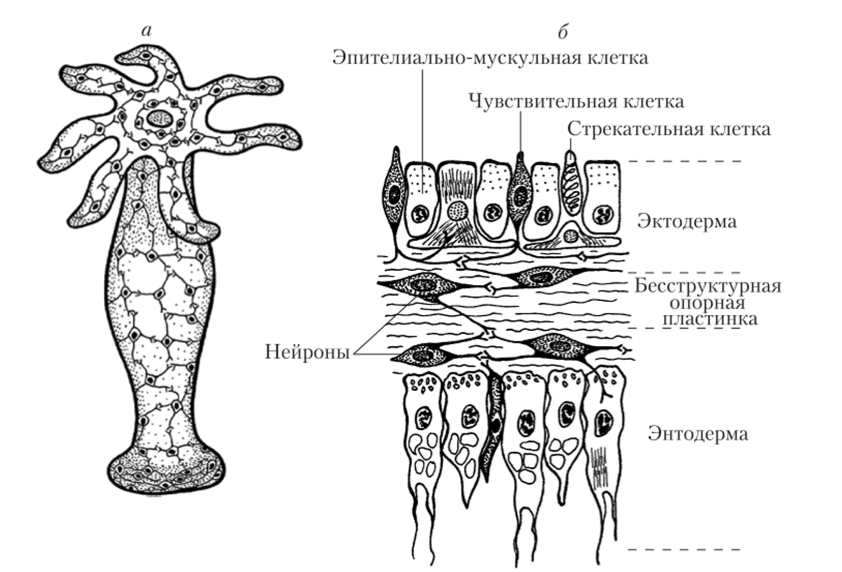
Татарин> Мы же говорим не о конкретной системе, которая сидит в конкретной коробке, а о том, что весёлая, неугомонная и никем не контролируемая толпа человеков добралась до штуковин, работы которых не понимает и по принципу построения штуковин вообще не может предсказать и контролировать.
И до каких же таких "штуковин, которые не понимает" добрались "никем неконтролируемые толпы (а с фига ли их вообще кто-то должен контролировать?) человеков"? До того, что можно сделать чатбота при достаточно большом кол-ве данных?
Татарин> В какой-то момент мы можем перейти черту, из-за которой нет возврата, и которая поделит всё на "до" и "после". Но уже не для людей.
Шкайнет?
И до каких же таких "штуковин, которые не понимает" добрались "никем неконтролируемые толпы (а с фига ли их вообще кто-то должен контролировать?) человеков"? До того, что можно сделать чатбота при достаточно большом кол-ве данных?
Татарин> В какой-то момент мы можем перейти черту, из-за которой нет возврата, и которая поделит всё на "до" и "после". Но уже не для людей.
Шкайнет?
В.с.с.О.>> А разница в том, что человек и машина работают на разных, так сказать уровнях. И из эффективности программы в узкой задачи игры в крестики-нолики не следует её применимость в других задачах или что с её помощью можно собрать "цифрового человека" или типа того.
Татарин> Эээ... раньше так можно было бы сказать, потому что алгоритм игры в крестики-нолики придумывал и запихивал в машину человек.
И всё точно также запихивает человек...
Татарин> Сейчас мы сделали машину, которая самостоятельно приобретает опыт, который будет использован в её дальнейшем функционировании. Мы только имеем некоторый контроль над выбором этого опыта, не более... но и то - интенсивно работаем над тем, чтобы этот контроль утратить, и дать машине возможность учиться полностью самостоятельно.
Нифига подобного. Для создания таких LLM собираются ТЫСЯЧИ человек, которые ВРУЧНУЮ набирают десятки же тысяч текстовых сообщений, пишут алгоритмы парсинга для этого текста и так далее. Это не какой-то "некоторый контроль над выбором этого опыта". Это даже не кормление с ложечки... Это тупо брутфорс.
Татарин> Зацикливаться на алгоритме, который делает этот процесс возможным, столь же осмысленно, как утверждать, что раз разума нет в атоме углерода, то его не может быть и в человеке. Человек точно так же состоит из вполне просчитываемых элементарных процессов, как и большая нейросеть, но, как и нейросеть, количество этих процессов даёт новое качество.
Ну да, можно же в облаках летать, зачем эта ваша приземлённая физика и математика...
Какого-то особого кач-ва
Татарин> Это вообще неважно. В смысле, то, на каких конкретных текстах натаскивали машину. Важно то, что она натаскивается.
Так всё, делаем сверхИИ на линейных моделях, блджад!!
Татарин> Не так даже важно, что она играет именно в правильно угадывание слов. Точно так же она могла бы играть в правильное угадывание действий.
Угу, в reinforcement learning "угадывание действий" либо полностью рандомное из всех возможных действий (всех возможных движений мотора робота/всех возможных ходов персонажа в игре и т.п.), либо это поиск в ЗАРАНЕЕ структурированном графе (как например для тактических/стратегических игр).
По сути не сильно лучше игры в крестики-нолики.
Татарин> Скайнет не обязательно должен "осознавать себя", уметь тонко чувствовать и писать стихи, ему вполне достаточно выцепить абстракции более глубокие, чем доступны человеку, и действовать по ним.
Да какие, мать его, абстракции?
Татарин> Понятен ли тебе весь тензор связей в совокупности и результаты вычислений при всех входных данных? Нет.
Татарин> Может ли быть так, что твоя наиболее вероятная реакция на выход машины в том тензоре прописана, равно как и оптимальная для машины реакция на тебя, а в твоей голове обратного нет? Да. Вот запросто.
А вот никакого запросто.
Татарин> Я не философ, мне пофигу, сколько ангелов могут поместиться на транзисторе, можно ли это высчисление назвать "мышлением" и т.п. демагогия. Называйте это не "мышлением ИИ", а "сепулением сепулькария" - пофиг. Конечный результат применения подобных систем может на выходе дать нечто абсолютно неуправляемое, для чего ты сам будет эффективным объектом управления.
Тут не больше "управления человеком", чем в каком-нибудь водопроводе.
Татарин> Не пофигу то, насколько глубокие связи, зависимости, паттерны при этом применяются. Реально, масса примеров того, что глубина паттернов - уже сравнима с тем, чем может средний человек. Ну или пусть даже туповатый человек, это без разницы, по сути.
Реально нет никаких примеров этой чудесной "глубины паттернов". Там были буквально десятки тысяч стандартизированных примеров генерации текста, и этот текст просто генерируется. Всё. Вера в чудеса вообще крупнейшая ошибка в ML. Пока ты не придумаешь, где и как получить данные и как их обработать, и какой архитектурой, никакого чуда не произойдёт.
Это реально не сильно далеко от переводчика, только вместо маппинга текста на одном языке на текст на другом языке, тут маппинг сферического в вакууме вопроса на сферический в вакууме контекст. И всё.
Татарин> Да пофигу на работу мозга. Неважно, как работает он, как работает машина, важна функциональная схожесть. Да, пока в одном конкретном аспекте. И? Фигли толку, если работы идут далее?
И НИКАКОЙ ФУНКЦИОНАЛЬНОЙ СХОЖЕСТИ НЕТ. Как искусственные нейросети и реальный мозг это как ракета из пластиковой бутылки и Saturn V.
Татарин> Это вот тот самый случай, когда "за деревьями не видит лес". Да, и что? Это понятно, но какая разница, как именно реализована система вычисления сложных связей и применения вычисленного?
Да и то, что там словарик принципиально ограничен. Если токенизатор обнаружит последовательность символов, которой нет в словаре, он просто её пометит [UNK] и всё. Т.е. даже возможные входные последовательности должны заранее закладываться человеком.
Татарин> А тупейший ли он? И не были ли правы "ИИ-оптимисты", когда говорили "нам просто нужно больше мощности"?
Пока природа человеческого мозга вообще непонятна, но он вполне уживается в <100 Ватт энергопотребления, без суперкомпьютеров с потреблением энергии как у небольшого городка, без всех текстовых данных интернета разом и без багов "папа, а где море".
Татарин> Во-первых, я из первых рук знаю про систему, в которой это ограничение красиво обошли. И я уверен, что этот принцип достаточно красив, чтобы товарищи не были бы единственными, кто до этого додумался.
Вот так вот, эти товарищи обошли, а индустрия, понимаешь ли, борется...
Есть конечно "скользящее окно", но это кривейший костыль, а не "принципиальное решение".
Там кроме этого нюансы, что если тренировочные данные были на условные 8К символов контекста, то при 16К контекста оно уже просаживается...
Татарин> Во-вторых, даже квадратичная зависимость - вовсе не настолько уж сильная, как тебе кажется и вполне подчиняется чисто экстенсивному преодолению. Мощности, которые сейчас используются для эмуляции нейросетей дико неприспособлены для этого (даже т.н. нейропроцессоры - чуток допиленные под векторные операции и SIMD обычные процы). Вот даже на этом можно сразу взять увеличение удельной производительности в тысячи-милионы раз и на рубль, и на ватт. Это даже если вынести за скобки квантовые вычисления, которые понемногу выходят из лаб (тут многие операции радикально сокращаются; например, нахождение максимального значения элемента в тензоре - существенно ускоряемая КК операция).
Да чего только в тысячи/миллионы раз, сразу рисуй 10101010101010101010101010101010, чего стесняться то.
Татарин> В-третьих, что ты не можешь или не хочешь понять... скорость работы это на самом деле не так важно, как тебе кажется. Есть вопросы, которые, в силу из сложности и глубины, людям не под силу, потому что время на решение растёт экспотенциально от сложности. Если машина может преодолеть барьер сложности - не так и важно, что она работает вдвое дольше, чем человек.
Ты ведь понимаешь, что перед "решением таких вопросов", нужно сначала доказать, что такие вопросы вообще есть?
Ну и каких-то сферических в вакууме машин нет, им тоже нужны данные и программное обеспечение, написанное людьми.
Татарин> У живых существ (человека конкретно) есть куда более серьёзные ограничения - см. популярные (или, если хочешь, не популярные, а научные, но они всё равно сейчас могут считаться популярными) работы того же Айзенка.
Пока серьёзные ограничения демонстрируют ИИ системы, с их памятью едва на один диалог. И не надо мне ссылаться тут на волшебные сферические в вакууме машины будущего.
Вполне возможно, что условный "ИИ общего назначения" будет создан в формате какого-нибудь синтетического/генетического модифицированного человека.
Татарин> Но вполне преодолимые для машины. Именно потому что она - неважно какой ценой - способна расширять свои память, матрицы корреляций, число одновременно рассматриваемых параметров и т.п.
Из этого расширения ничего не следует. Программа для игры в крестики-нолики играет в крестики нолики перебором всех возможных комбинаций даже на суперкомпьютере.
Татарин> Эээ... раньше так можно было бы сказать, потому что алгоритм игры в крестики-нолики придумывал и запихивал в машину человек.
И всё точно также запихивает человек...
Татарин> Сейчас мы сделали машину, которая самостоятельно приобретает опыт, который будет использован в её дальнейшем функционировании. Мы только имеем некоторый контроль над выбором этого опыта, не более... но и то - интенсивно работаем над тем, чтобы этот контроль утратить, и дать машине возможность учиться полностью самостоятельно.
Нифига подобного. Для создания таких LLM собираются ТЫСЯЧИ человек, которые ВРУЧНУЮ набирают десятки же тысяч текстовых сообщений, пишут алгоритмы парсинга для этого текста и так далее. Это не какой-то "некоторый контроль над выбором этого опыта". Это даже не кормление с ложечки... Это тупо брутфорс.
Татарин> Зацикливаться на алгоритме, который делает этот процесс возможным, столь же осмысленно, как утверждать, что раз разума нет в атоме углерода, то его не может быть и в человеке. Человек точно так же состоит из вполне просчитываемых элементарных процессов, как и большая нейросеть, но, как и нейросеть, количество этих процессов даёт новое качество.
Ну да, можно же в облаках летать, зачем эта ваша приземлённая физика и математика...
Какого-то особого кач-ва
Татарин> Это вообще неважно. В смысле, то, на каких конкретных текстах натаскивали машину. Важно то, что она натаскивается.
Так всё, делаем сверхИИ на линейных моделях, блджад!!
Татарин> Не так даже важно, что она играет именно в правильно угадывание слов. Точно так же она могла бы играть в правильное угадывание действий.
Угу, в reinforcement learning "угадывание действий" либо полностью рандомное из всех возможных действий (всех возможных движений мотора робота/всех возможных ходов персонажа в игре и т.п.), либо это поиск в ЗАРАНЕЕ структурированном графе (как например для тактических/стратегических игр).
По сути не сильно лучше игры в крестики-нолики.
Татарин> Скайнет не обязательно должен "осознавать себя", уметь тонко чувствовать и писать стихи, ему вполне достаточно выцепить абстракции более глубокие, чем доступны человеку, и действовать по ним.
Да какие, мать его, абстракции?
Татарин> Понятен ли тебе весь тензор связей в совокупности и результаты вычислений при всех входных данных? Нет.
Татарин> Может ли быть так, что твоя наиболее вероятная реакция на выход машины в том тензоре прописана, равно как и оптимальная для машины реакция на тебя, а в твоей голове обратного нет? Да. Вот запросто.
А вот никакого запросто.
Татарин> Я не философ, мне пофигу, сколько ангелов могут поместиться на транзисторе, можно ли это высчисление назвать "мышлением" и т.п. демагогия. Называйте это не "мышлением ИИ", а "сепулением сепулькария" - пофиг. Конечный результат применения подобных систем может на выходе дать нечто абсолютно неуправляемое, для чего ты сам будет эффективным объектом управления.
Тут не больше "управления человеком", чем в каком-нибудь водопроводе.
Татарин> Не пофигу то, насколько глубокие связи, зависимости, паттерны при этом применяются. Реально, масса примеров того, что глубина паттернов - уже сравнима с тем, чем может средний человек. Ну или пусть даже туповатый человек, это без разницы, по сути.
Реально нет никаких примеров этой чудесной "глубины паттернов". Там были буквально десятки тысяч стандартизированных примеров генерации текста, и этот текст просто генерируется. Всё. Вера в чудеса вообще крупнейшая ошибка в ML. Пока ты не придумаешь, где и как получить данные и как их обработать, и какой архитектурой, никакого чуда не произойдёт.
Это реально не сильно далеко от переводчика, только вместо маппинга текста на одном языке на текст на другом языке, тут маппинг сферического в вакууме вопроса на сферический в вакууме контекст. И всё.
Татарин> Да пофигу на работу мозга. Неважно, как работает он, как работает машина, важна функциональная схожесть. Да, пока в одном конкретном аспекте. И? Фигли толку, если работы идут далее?
И НИКАКОЙ ФУНКЦИОНАЛЬНОЙ СХОЖЕСТИ НЕТ. Как искусственные нейросети и реальный мозг это как ракета из пластиковой бутылки и Saturn V.
Татарин> Это вот тот самый случай, когда "за деревьями не видит лес". Да, и что? Это понятно, но какая разница, как именно реализована система вычисления сложных связей и применения вычисленного?
Да и то, что там словарик принципиально ограничен. Если токенизатор обнаружит последовательность символов, которой нет в словаре, он просто её пометит [UNK] и всё. Т.е. даже возможные входные последовательности должны заранее закладываться человеком.
Татарин> А тупейший ли он? И не были ли правы "ИИ-оптимисты", когда говорили "нам просто нужно больше мощности"?
Пока природа человеческого мозга вообще непонятна, но он вполне уживается в <100 Ватт энергопотребления, без суперкомпьютеров с потреблением энергии как у небольшого городка, без всех текстовых данных интернета разом и без багов "папа, а где море".
Татарин> Во-первых, я из первых рук знаю про систему, в которой это ограничение красиво обошли. И я уверен, что этот принцип достаточно красив, чтобы товарищи не были бы единственными, кто до этого додумался.
Вот так вот, эти товарищи обошли, а индустрия, понимаешь ли, борется...
Есть конечно "скользящее окно", но это кривейший костыль, а не "принципиальное решение".
Там кроме этого нюансы, что если тренировочные данные были на условные 8К символов контекста, то при 16К контекста оно уже просаживается...
Татарин> Во-вторых, даже квадратичная зависимость - вовсе не настолько уж сильная, как тебе кажется и вполне подчиняется чисто экстенсивному преодолению. Мощности, которые сейчас используются для эмуляции нейросетей дико неприспособлены для этого (даже т.н. нейропроцессоры - чуток допиленные под векторные операции и SIMD обычные процы). Вот даже на этом можно сразу взять увеличение удельной производительности в тысячи-милионы раз и на рубль, и на ватт. Это даже если вынести за скобки квантовые вычисления, которые понемногу выходят из лаб (тут многие операции радикально сокращаются; например, нахождение максимального значения элемента в тензоре - существенно ускоряемая КК операция).
Да чего только в тысячи/миллионы раз, сразу рисуй 10101010101010101010101010101010, чего стесняться то.
Татарин> В-третьих, что ты не можешь или не хочешь понять... скорость работы это на самом деле не так важно, как тебе кажется.
Есть вопросы, которые, в силу из сложности и глубины, людям не под силу, потому что время на решение растёт экспотенциально от сложности. Если машина может преодолеть барьер сложности - не так и важно, что она работает вдвое дольше, чем человек.Ты ведь понимаешь, что перед "решением таких вопросов", нужно сначала доказать, что такие вопросы вообще есть?
Ну и каких-то сферических в вакууме машин нет, им тоже нужны данные и программное обеспечение, написанное людьми.
Татарин> У живых существ (человека конкретно) есть куда более серьёзные ограничения - см. популярные (или, если хочешь, не популярные, а научные, но они всё равно сейчас могут считаться популярными) работы того же Айзенка.
Пока серьёзные ограничения демонстрируют ИИ системы, с их памятью едва на один диалог. И не надо мне ссылаться тут на волшебные сферические в вакууме машины будущего.
Вполне возможно, что условный "ИИ общего назначения" будет создан в формате какого-нибудь синтетического/генетического модифицированного человека.
Татарин> Но вполне преодолимые для машины. Именно потому что она - неважно какой ценой - способна расширять свои память, матрицы корреляций, число одновременно рассматриваемых параметров и т.п.
Из этого расширения ничего не следует. Программа для игры в крестики-нолики играет в крестики нолики перебором всех возможных комбинаций даже на суперкомпьютере.
Татарин> - поведение нейросети задаётся её опытом, а не зашитым алгоритмом. Опыт нейросети частично контролируется человеком (частично, потому что человек не понимает как минимум в полной мере, а часто не понимает вообще, что это за опыт). Алгоритм вычисления нейросети в данном случае низкий, "физический" уровень, точно так же, как для игры в крестики-нолики - транзисторы, а для человека - ДНК. Ни в транзисторах, ни в процессоре, ни в алгоритме нейросети, ни в ДНК, ни в нейронах нет разума.
У НЕЙ НЕТ ОПЫТА.
Это точно такая же игра в крестики-нолики, но с более сложным препроцессингом и теорвером с некоторой рандомностью.
У НЕЙ НЕТ ОПЫТА.
Это точно такая же игра в крестики-нолики, но с более сложным препроцессингом и теорвером с некоторой рандомностью.
Sandro> С предсказуемым систематическим впаданием в шизофазию. Напомню, основным признаком шизофазической речи является хорошая локальная согласованность — и одновременно полная бредовость в общем виде. Сто кирпичей.
Ну так нюансы в ограниченном контексте и в коротких текстах при тренировке...
Глубина, понимаешь ли, закономерностей и мышления...
Ну так нюансы в ограниченном контексте и в коротких текстах при тренировке...
Глубина, понимаешь ли, закономерностей и мышления...
Татарин> Следующий шаг - непосредственное взаимодействие с реальностью через выполнение спланированных действий и получение обратной связи непосредственно от реальности.
Не, следующий шаг - это проблемы, возможно непреодолимые в обозримой перспективе, с этим самым получением обратной связи.
Татарин> <...> но это вопрос времени, технически задача (для написания нейросетью кода) достаточно понятна и проста в "общем виде" <...> С железом - тоже не так сложно, как кажется <...> Генерировать, закачивать в матрицу, проверять работу, делать выводы, генерировать... в общем, нормальный цикл обучения, почти независимый от человека.
Типичная жвачка про чисто технические проблемы. Точно такую же жвачку пишут с 50-х годов, а на практике даже текущие системы прикрутить в продакшн - задача крайне сложная и дорогостоящая.
Татарин> Ты смотришь на БЯМ как на генераторы текста, а это неправильно.
Вполне правильно смотреть на генератор текста, как на, чёрт возьми, генератор текста!
Татарин> Примерно как простые идеи разных свёрточных сетей, резидуал и чего-там-ещё совершили прорыв в распознавании образов.
Обрати внимание, что этот прорыв в итоге "выдохся". Для дальнейшего развития нужны новые открытия. Которые может будут, а может наступит стагнация индустрии.
Татарин> Неважно, что первые сверточные сети работали с примерами, достойными персептронов и показывали просто "результат получше" в распознавании простых рукописных символов. Это был прорыв, потому что было показано куда и как можно двигаться.
Обрати внимание: просто показало направление, куда можно двигаться. Без гарантий какого-либо успеха. И до сих пор проблемы распознавания область активных исследований, и до человека таким системам ещё идти и идти, не факт, что у людей эти системы хотя бы отдалённо напоминают текущие системы.
Татарин> Эмерджентные эффекты показывают, что так-то мы на правильном пути к интеллекту (или, для педантов, к чему-то неотличимому от него на массе практически важных задач).
Опять же, никаких фактов и гарантий, а только спекуляций. Выше принципиальные проблемы уже назывались.
В начале 20-го века был весьма положительный опыт использования дирижаблей в гражданской и военной авиации. Казалось бы, вот признаки правильного пути. Но нет, по этому пути в итоге никто успешно не прошёл.
И тем более нет оснований полагать, про какую-то возможность "выцепить более глубокие абстракции, чем человек" и прочие обожествления ИИ.
Не, следующий шаг - это проблемы, возможно непреодолимые в обозримой перспективе, с этим самым получением обратной связи.
Татарин> <...> но это вопрос времени, технически задача (для написания нейросетью кода) достаточно понятна и проста в "общем виде" <...> С железом - тоже не так сложно, как кажется <...> Генерировать, закачивать в матрицу, проверять работу, делать выводы, генерировать... в общем, нормальный цикл обучения, почти независимый от человека.
Типичная жвачка про чисто технические проблемы. Точно такую же жвачку пишут с 50-х годов, а на практике даже текущие системы прикрутить в продакшн - задача крайне сложная и дорогостоящая.
Татарин> Ты смотришь на БЯМ как на генераторы текста, а это неправильно.
Вполне правильно смотреть на генератор текста, как на, чёрт возьми, генератор текста!
Татарин> Примерно как простые идеи разных свёрточных сетей, резидуал и чего-там-ещё совершили прорыв в распознавании образов.
Обрати внимание, что этот прорыв в итоге "выдохся". Для дальнейшего развития нужны новые открытия. Которые может будут, а может наступит стагнация индустрии.
Татарин> Неважно, что первые сверточные сети работали с примерами, достойными персептронов и показывали просто "результат получше" в распознавании простых рукописных символов. Это был прорыв, потому что было показано куда и как можно двигаться.
Обрати внимание: просто показало направление, куда можно двигаться. Без гарантий какого-либо успеха. И до сих пор проблемы распознавания область активных исследований, и до человека таким системам ещё идти и идти, не факт, что у людей эти системы хотя бы отдалённо напоминают текущие системы.
Татарин> Эмерджентные эффекты показывают, что так-то мы на правильном пути к интеллекту (или, для педантов, к чему-то неотличимому от него на массе практически важных задач).
Опять же, никаких фактов и гарантий, а только спекуляций. Выше принципиальные проблемы уже назывались.
В начале 20-го века был весьма положительный опыт использования дирижаблей в гражданской и военной авиации. Казалось бы, вот признаки правильного пути. Но нет, по этому пути в итоге никто успешно не прошёл.
И тем более нет оснований полагать, про какую-то возможность "выцепить более глубокие абстракции, чем человек" и прочие обожествления ИИ.
Sandro> Она может только воровать знания у людей. Но не создавать свои. В этом-то и дело.
Там нет "знаний".
Гугл-переводчик не выдумает вам новый язык. Он, с некоторым шансем и некоторой точностью переведёт тебе текст с языка 1 на язык 2.
LLM не даст тебе принципиально новых знаний. Она, с некоторым шансем и некоторой точностью переведёт "вопрос 1-ответ 1-вопрос 2-ответ 2-вопрос 3" на сферический в вакууме ответ 3.
Чудес там нет и быть не может.
Там нет "знаний".
Гугл-переводчик не выдумает вам новый язык. Он, с некоторым шансем и некоторой точностью переведёт тебе текст с языка 1 на язык 2.
LLM не даст тебе принципиально новых знаний. Она, с некоторым шансем и некоторой точностью переведёт "вопрос 1-ответ 1-вопрос 2-ответ 2-вопрос 3" на сферический в вакууме ответ 3.
Чудес там нет и быть не может.
Татарин> А разве это не то, что делает человек (которого мы считаем разумным за неимением других альтернатив с таким прилагательным)? Он берёт цепочку прошлых событий и составляет некую прогнозную цепочку (или цепочку
действий) или цепочку действий, которые необходимо предпринять. Или одну цепочку на основе другой.
Вообще не факт.
Есть 100500 нюансов в виде выборочной памяти, действий на рефлексах, концепции уверенности/неуверенности и т.д..
Вот например, при выполнении многих сложных операций и действий человек становится быстрее и продуктивнее при длительном выполнении этого задания казалось бы, для большего кач-ва выполнения задания нужно иметь более точную прогнозную цепочку, для получения которой нужен более сложный процесс, но он почему-то становится только быстрее! Например, опытный художник быстрее рисует, опытный водитель быстрее паркуется.
Да чёрт возьми, человек может уже в зрелом возрасте выучить новый язык, а то и несколько.
И обрати внимание, это всё происходит без терабайтов данных и *бафлопсов вычислительной мощности.
Татарин> "Мир есть текст"© Толкиен, всё, должным образом предобработаное, - есть токены.
Эх, напоминает отцов-основателей ИИ, у которых проблемы загрузки реальных в абстрактные токены считалось чем-то принципиально решаемым и тем, что можно "отложить в сторонку", и сконцентрироваться на решении проблем "семантической обработки данных"...
Короче, на практике ничего не срослось.
Татарин> Если ты подумаешь, то даже невербализованная цепочка рассуждений человека - суть операция над цепочкой токенов-понятий.
Опять же, такое же сомнительное обобщение всего и вся, аля символьный ИИ.
Татарин> "Распознавание" и есть токенизация видео-, звуковых, или там каких-то ещё образов. Сведение сложного непрерывного образа внешнего мира к счётному количеству известных объектов-токенов.
см выше.
Татарин> Мы имеем технологию сопоставляющую внешнему миру ряд токенов. Мы (уже давно) имеем технологию, "разворачивающую" токены в действия. У наших машин давно уже есть "зрение", "слух", "тело", не хватало "разума". Ну или разума.
Нет ни "зрения", ни "слуха", ни "тела", ни "разума". Не факт, что их вообще можно создать в произвольном порядке один без другого.
Вот например, как прикрутить,
Татарин> Собссно, машина, которая работает над сложными цепочками токенов - и есть "мыслящая" (или мыслящая) машина.
А машина, работающая над символами с помощью последовательных логических операций, тоже зело "мыслящая", только вот на практике недееспособная и по сути бесполезно "мыслящая" в сферическом вакууме.
Татарин> Как и необученый человек. С детьми ты всяко же общался, верно?
Дети потребляют куда меньше энергии, куда быстрее и куда более разнообразно обучаются.
Татарин> Моя философия тут проста: если эмерджентные эффекты заменителя "интеллекта" функционально схожи с тем, что даёт "интеллект" до неотличимости, то с практической точки зрения заменитель интеллекта работает. "Настоящий" ли это интеллект - неважно.
Генерировать текст "до неотличимости" научились ещё во времена ELIZA. И из "неотличимости" вообще не следует даже близкой схожести механизмов работы. Эмерджетность тоже имеет свои ограничения, и экстраполировать её без оснований - глупо. Тут же система СПЕЦИАЛЬНО настроена на генерацию человекоподобных текстов, так что их неотличимость от таковых вообще неудивительна.
Татарин> Большое количество чисто человеческих фич не нужно чтобы водить машину, составлять этот текст, писать код или разрабатывать теорию суперструн.
Вот далеко не факт. Смотри тот же символьный ИИ. Тоже откидывали почти всё вбок как "ненужное".
В конце концов может статься так, что для реализации всех способностей человеческого мозга понадобится иметь биопанк в виде искусственно выращенных и сшитых между собой живых нейронов, а все остальные подходы будут чисто теоретическими, аля полёт на Луну на ракете с топливом из прелой соломы.
Татарин> Это всё действия, которые может делать машина точно так же, как машина научилась прилично играть в го.
Вот нифига "прилично играть в го" она не научилась. Той адаптации и той динамики, что у человека там нет. Буквально на второй игре чемпион понял, как ультимативно законтрить атаку машины, а на 4 игре он уже победил, уже узнал слабости игры машины и уже мог их эксплуатировать сколько ему угодно. При этом этот чемпион УЖЕ умеет гораздо больше той программы и имеет гораздо больший потенциал в обучении. Он может просто после турнира прийти домой и пожарить себе котлетки, попутно прочитав рецепт какого-нибудь нового блюда и тоже приготовив его, например.
Татарин> Я не понимаю, как и почему вы проводите между этими вещами черту.
Я не вижу причин, почему поршневой винтовой самолёт не может своим ходом долететь до Альфа Центавры. И то и то полёт, разница только количественная, в конце концов.
Я не знаю, как и почему вы проводите здесь черту.
действий) или цепочку действий, которые необходимо предпринять. Или одну цепочку на основе другой.
Вообще не факт.
Есть 100500 нюансов в виде выборочной памяти, действий на рефлексах, концепции уверенности/неуверенности и т.д..
Вот например, при выполнении многих сложных операций и действий человек становится быстрее и продуктивнее при длительном выполнении этого задания казалось бы, для большего кач-ва выполнения задания нужно иметь более точную прогнозную цепочку, для получения которой нужен более сложный процесс, но он почему-то становится только быстрее! Например, опытный художник быстрее рисует, опытный водитель быстрее паркуется.
Да чёрт возьми, человек может уже в зрелом возрасте выучить новый язык, а то и несколько.
И обрати внимание, это всё происходит без терабайтов данных и *бафлопсов вычислительной мощности.
Татарин> "Мир есть текст"© Толкиен, всё, должным образом предобработаное, - есть токены.
Эх, напоминает отцов-основателей ИИ, у которых проблемы загрузки реальных в абстрактные токены считалось чем-то принципиально решаемым и тем, что можно "отложить в сторонку", и сконцентрироваться на решении проблем "семантической обработки данных"...
Короче, на практике ничего не срослось.
Татарин> Если ты подумаешь, то даже невербализованная цепочка рассуждений человека - суть операция над цепочкой токенов-понятий.
Опять же, такое же сомнительное обобщение всего и вся, аля символьный ИИ.
Татарин> "Распознавание" и есть токенизация видео-, звуковых, или там каких-то ещё образов. Сведение сложного непрерывного образа внешнего мира к счётному количеству известных объектов-токенов.
см выше.
Татарин> Мы имеем технологию сопоставляющую внешнему миру ряд токенов. Мы (уже давно) имеем технологию, "разворачивающую" токены в действия. У наших машин давно уже есть "зрение", "слух", "тело", не хватало "разума". Ну или разума.
Нет ни "зрения", ни "слуха", ни "тела", ни "разума". Не факт, что их вообще можно создать в произвольном порядке один без другого.
Вот например, как прикрутить,
Татарин> Собссно, машина, которая работает над сложными цепочками токенов - и есть "мыслящая" (или мыслящая) машина.
А машина, работающая над символами с помощью последовательных логических операций, тоже зело "мыслящая", только вот на практике недееспособная и по сути бесполезно "мыслящая" в сферическом вакууме.
Татарин> Как и необученый человек. С детьми ты всяко же общался, верно?
Дети потребляют куда меньше энергии, куда быстрее и куда более разнообразно обучаются.
Татарин> Моя философия тут проста: если эмерджентные эффекты заменителя "интеллекта" функционально схожи с тем, что даёт "интеллект" до неотличимости, то с практической точки зрения заменитель интеллекта работает. "Настоящий" ли это интеллект - неважно.
Генерировать текст "до неотличимости" научились ещё во времена ELIZA. И из "неотличимости" вообще не следует даже близкой схожести механизмов работы. Эмерджетность тоже имеет свои ограничения, и экстраполировать её без оснований - глупо. Тут же система СПЕЦИАЛЬНО настроена на генерацию человекоподобных текстов, так что их неотличимость от таковых вообще неудивительна.
Татарин> Большое количество чисто человеческих фич не нужно чтобы водить машину, составлять этот текст, писать код или разрабатывать теорию суперструн.
Вот далеко не факт. Смотри тот же символьный ИИ. Тоже откидывали почти всё вбок как "ненужное".
В конце концов может статься так, что для реализации всех способностей человеческого мозга понадобится иметь биопанк в виде искусственно выращенных и сшитых между собой живых нейронов, а все остальные подходы будут чисто теоретическими, аля полёт на Луну на ракете с топливом из прелой соломы.
Татарин> Это всё действия, которые может делать машина точно так же, как машина научилась прилично играть в го.
Вот нифига "прилично играть в го" она не научилась. Той адаптации и той динамики, что у человека там нет. Буквально на второй игре чемпион понял, как ультимативно законтрить атаку машины, а на 4 игре он уже победил, уже узнал слабости игры машины и уже мог их эксплуатировать сколько ему угодно. При этом этот чемпион УЖЕ умеет гораздо больше той программы и имеет гораздо больший потенциал в обучении. Он может просто после турнира прийти домой и пожарить себе котлетки, попутно прочитав рецепт какого-нибудь нового блюда и тоже приготовив его, например.
Татарин> Я не понимаю, как и почему вы проводите между этими вещами черту.
Я не вижу причин, почему поршневой винтовой самолёт не может своим ходом долететь до Альфа Центавры. И то и то полёт, разница только количественная, в конце концов.
Я не знаю, как и почему вы проводите здесь черту.
Татарин> Ты погоди-погоди ещё.
Уже полвека ждём...

Татарин> Просто эта штука на обучении верит всему абсолютно, как 3-летний ребёнок (а скорее - как младенец). Она не "умеет" иначе, её напрямую заливают данными.
Тут даже НЕТ понятия доверия.
Модели для обучения данные вообще не нужны, если на то пошло. Они больше нужны функции вычисления ошибки. Она построена по принципу "всё правильно, что в тексте для обучения".
Уже полвека ждём...
Татарин> Просто эта штука на обучении верит всему абсолютно, как 3-летний ребёнок (а скорее - как младенец). Она не "умеет" иначе, её напрямую заливают данными.
Тут даже НЕТ понятия доверия.
Модели для обучения данные вообще не нужны, если на то пошло. Они больше нужны функции вычисления ошибки. Она построена по принципу "всё правильно, что в тексте для обучения".
Реклама Google — средство выживания форумов :)
Naib> И в итоге всё одно упрёшься в личный опыт. Практика - критерий истины. Придёшь к вопросам, которые невозможно разрешить теоретически, а нужно проверять экспериментом. И хорошо ещё если там всё пойдёт по прогнозируемому пути, а не сикось-накось как обычно...
Вот +100500. Мне из-за этого концепции "гомункулов" и прочих "бестелесных" интеллектов не нравятся.
Вот +100500. Мне из-за этого концепции "гомункулов" и прочих "бестелесных" интеллектов не нравятся.
Copyright © Balancer 1997..2023
Создано 29.03.2023
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 29.03.2023
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
